КАК БОЛЬШИЕ ДАННЫЕ СТАНОВЯТСЯ ОБЪЕКТОМ МАНИПУЛЯЦИИ НА САЙТАХ ЗНАКОМСТВ
Создатели американского сайта eHarmony раньше других осознали, что чем больше сведений они будут использовать и чем более замысловатые алгоритмы напишут, тем больше шанс подбирать людям подходящую пару, а не просто знакомить их и оставлять им самим решение вопроса о совместимости характеров.
eHarmony даже рекламируется не как простой сайт знакомств, а как средство поиска постоянных спутников жизни. Свой успех разработчики измеряют в количестве браков между людьми, встретившимися через их сервис. Соответственно, знакомства на одну ночь достижением не считаются, и в eHarmony даже подсчитывают статистику разрывов отношений и разводов: она на два процента меньше, чем на других аналогичных сайтах. Опросы супружеских пар, сложившихся благодаря сайтам знакомств, говорят о том, что в каждом четвёртом браке такого рода «повинна» именно eHarmony. Авторы сервиса с гордостью отчитываются о том, что в 2005 году число браков, ежедневно заключаемых их пользователями, составляло 90, к 2007-му эта цифра выросла уже до 236, а к 2009-му — аж до 542. Пять сотен свадеб в день — это несомненный успех! Как удалось достичь таких показателей? Не обошлось без анализа «больших данных» и машинного обучения. Первым делом каждому пользователю предлагается заполнить анкету из 150 пунктов. В 2000-м, когда сервис только открылся, в анкете было 500 вопросов, но с каждым годом разработчики изыскивали способы сокращать опросник, при этом не теряя возможности получить ценную информацию о привычках, предпочтениях и складе ума пользователей. Установлено, например, что любителям фастфуда сложнее найти любовь, чем людям, выбирающим другие виды пищи. Двое поедателей гамбургеров вовсе не составляют счастливую толстую пару, а лишь испытывают взаимную неприязнь вдвое сильнее. Зато поклонники сыроедения замечательно сходятся между собой.
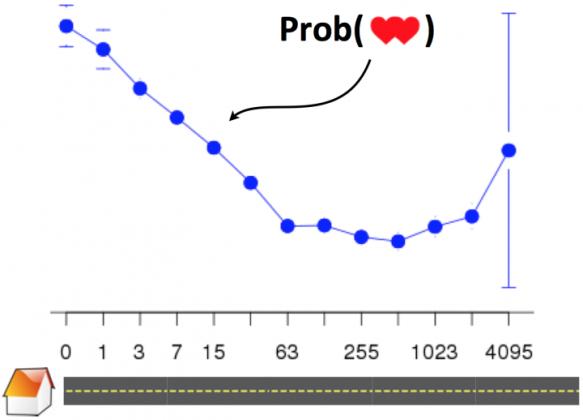
И это далеко не единственный пример неочевидной на первый взгляд статистики, полученной из анализа «больших данных». Никто не будет сомневаться в том, что чем ближе живут люди, тем вероятнее из их знакомства что-нибудь получится.
Но после определённого расстояния на графике виден скачок: необходимость в дальнем путешествии может не только разъединять, но и сближать.
Понятно, что люди всегда стараются выставлять себя в анкетах с лучшей стороны, но разработчики отлично об этом осведомлены. Секрет в таком составлении вопросов, чтобы выявлять психологические черты, а не следовать тому образу, который человек выбирает для себя.
Анализу подвергаются не только анкеты, но и поведение на сайтеОбычно болтливые пользователи без труда находят друг друга, но в eHarmony пытаются разбить эту тенденцию и добиваются баланса. Сервис учитывает количество отправляемых сообщений и знает, кто насколько общителен. eHarmony старается знакомить болтунов с молчунами: пусть стеснительным персонам бывает непросто найти общий язык друг с другом, зато в беседе с болтунами они раскрывают себя намного быстрее.
Все эти манипуляции с данными требуют серьёзных вычислительных ресурсов и соответствующей инфраструктуры. Данные eHarmony хранятся в собственном дата-центре. На серверы установлен фреймворк Hadoop, работающий с отказоустойчивой файловой системой HDFS. Apache Hive применяется для того, чтобы иметь возможность делать запросы к Hadoop при помощи языка запросов, напоминающего SQL, и формировать модели для алгоритмов машинного обучения. И, наконец, для веб-фронтенда в компании применяют MongoDB.
Искусственный интеллект, который даёт eHarmony возможность извлекать пользу из статистики за последние десять лет, основан на опенсорсной библиотеке Vowpal Wabbit. Это чрезвычайно гибкое и легко расширяемое средство, отличающееся к тому же почти бесконечной масштабируемостью. Автор Vorpal Wabbit Джон Лэнгфорд, вначале работавший над VW в Yahoo, а затем перешедший в Microsoft Research, придумал, реализовал и оптимизировал алгоритм машинного обучения, не требующий загружать данные в память целиком. Vorpal Wabbit способен за час обработать набор данных из 1012 записей, разнесённых на тысяче серверов. Помимо машинного обучения, в eHarmony используются и генетические алгоритмы. На данный момент у eHarmony 640 серверов с примерно 5 000 процессорных ядер и 2 петабайта данных. Источник: Сomputerra.RU - https://www.computerra.ru/89191/eharmony-bigdata/Опубликовано: 29.01.2013 |
|




Все права на информацию для посетителей разрешены © 2011 - 2024 - Zadereyko.INFO